
Hi, I am Huy (or Ken) ...
- Current Meta's Research Scientist in the Instagram Well-Being Fairness team.
- Ex-Facebook, Ex-Amazon, and Ex-Pinterest intern.
- NSF funded Ph.D. Computer Science Student at North Carolina State University.
- Machine Learning and Software Engineer Researcher at the RAISE Lab (NCSU).
I am passionate about the synergy of human and AI to improve software development specifically and socio-technical ecosystems generally.
During the day I'm an Engineer and Researcher in the making. I was working with Dr. Tim Menzies to solve real-world problems empirically especially by designing and building AI tools that are human-focused/explainable to better software development in (1) Computational Science community specifically and (2) Software Engineering community holistically. My vision is having the human in control when AI's abilities can leverage on human's expertise as a cohesive body instead of AI replacing human.
Beside daily learning and doing rocket sciences, I enjoy playing badminton, cooking, poetry, and playing guitar. For more information, please contact me! Or have a look at my CV below.
Work
Dept of Computer Science @ NCSU
Graduate Research and Teaching Assistant• August, 2016 - Present
Amazon.com Services, LLC
Applied Scientist Intern• May - August, 2020
ML Engineer Intern• May - August, 2019
YouNet & Gumi
Data Science Intern• May - August, 2017
Dept of Mathematics @ AppState
Undergraduate Assistant• August, 2012 - August, 2016
AppState University Housing
Resident Assistant and VP of RA Council• January, 2013 - August, 2015
Education
North Carolina State University
PhD in Computer Science• August 2019 - Present
MS in Computer Science• August 2016 - May 2019
Graduate Merit Fellowship ($10,000+) for GPA 3.5+
Appalachian State University
Bachelor of Science in Computational Mathematics • 2011 - 2015
Minor in Computer Science
Graduated with Magna Cum Laude, 3.80/4.0. Top 5% of my graduated class.
Publications
Huy Tu, Rishabh Agrawal, Tim Menzies
Submitted for ICSE, 2020
We seek quantitative evidence (from dozens of Comptutational Science projects housed in Github) for 13 previously published conjectures about scientific software development in the literature. In all, we explore three groups of beliefs about (1) the nature of scientific challenges; (2) the implications of limitations of computer hardware; and (3) the cultural environment of scientific software development. We find that four cannot be assessed with respect to the Github data. Of the others, only three can be endorsed.
Huy Tu, George Papadimitriou, Mariam Kiran, Cong Wang, Anirban Mandal, Ewa Deelmanban, Tim Menzies
Submitted for ESA Journal, 2020
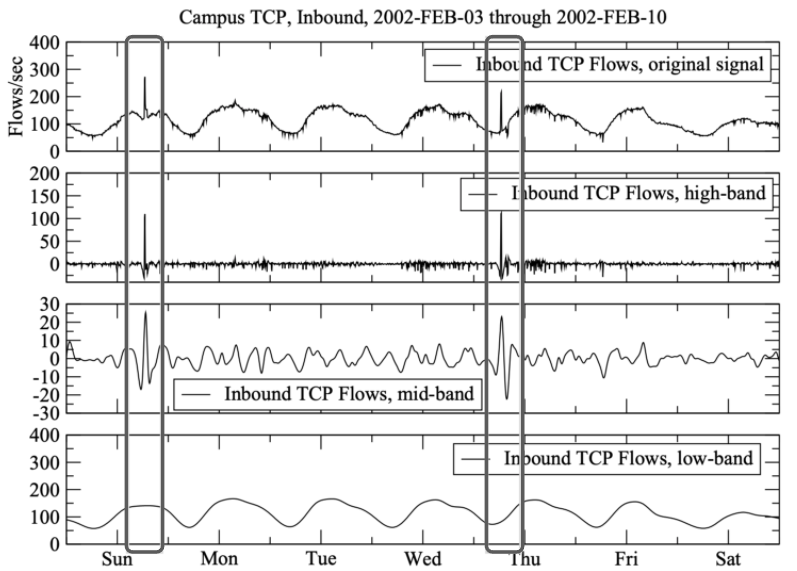
An anomaly detector, X-FLASH, identifies faulty TCP signatures in Scientific Workflows (SW). X-FLASH outperformed SOTA up to 40% relatively in recall within 30 evaluations. This implies (1) a proof-of-concept of tuning SE method for SW and (2) the necessity of tuning for future SW work.
Zhe Yu, Huy Tu, Fahmid M. Fahid, Tim Menzies
Submitted for TSE, 2020
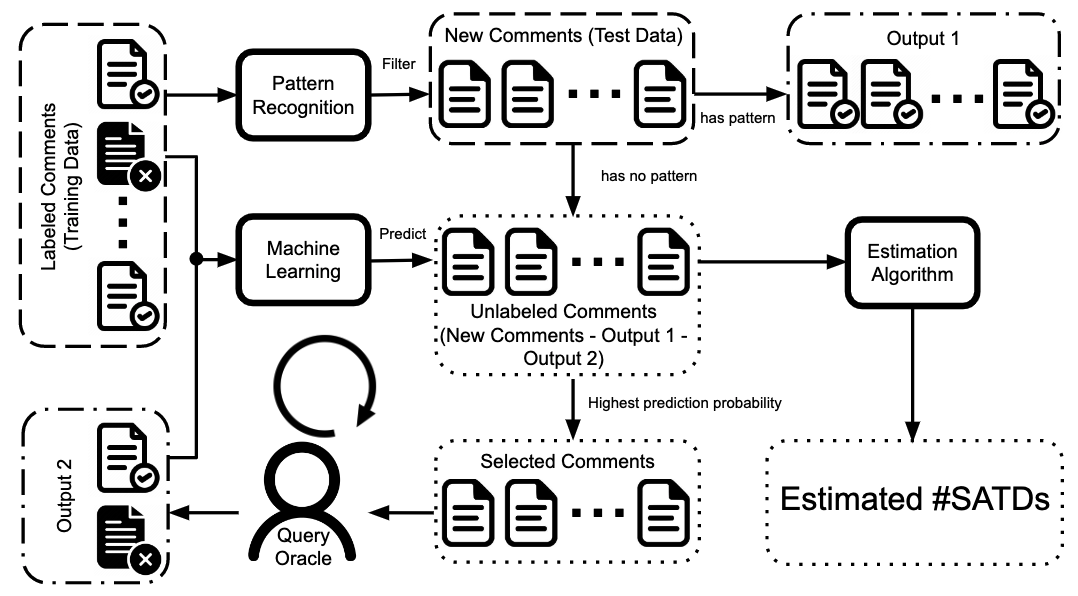
Keeping track of and managing the self-admitted technical debts (SATDs) is important to maintaining a healthy software project. To solve the above problems, we propose a two-step framework called Jitterbug for identifying SATDs by first finding the "easy to find" SATDs automatically with close to 100% precision via a novel pattern recognition technique, then applying ML techniques to assist human experts in manually identifying the rest "hard to find" SATDs with reduced human effort. Our simulation studies on ten software projects show that Jitterbug can identify SATDs more efficiently (with less human effort) than the prior state of the art methods.
Huy Tu, Zhe Yu, Tim Menzies
IEEE Transaction of Software Engineering (TSE), 2019
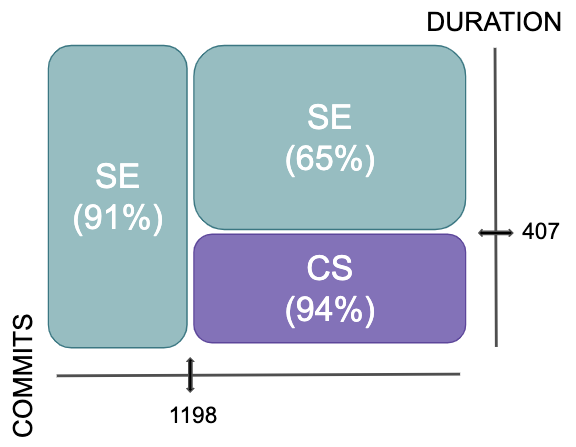
Standard automatic methods for recognizing problematic development commits can be greatly improved via the incremental application of human+artificial expertise. In this approach, called EMBLEM, an AI tool first explore the software development process to label commits that are most problematic. Humans then apply their expertise to check those labels (perhaps resulting in the AI updating the support vectors within their SVM learner).
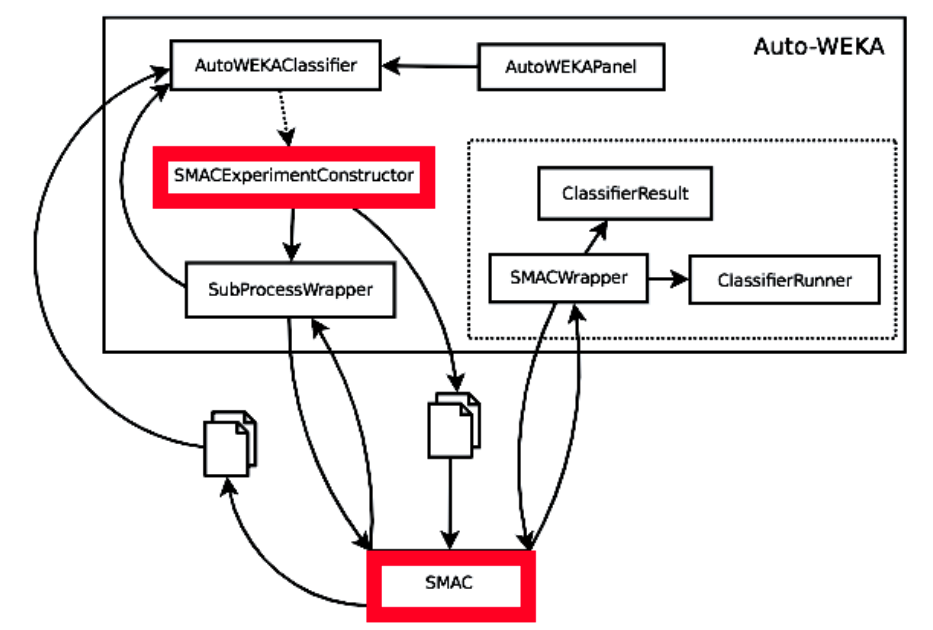
Huy Tu, Vivek Nair
Software Analytics Workshop @ FSE (SWAN), 2018 (Accepted)
Hyperparameter tuning is the black art of automatically finding a good combination of control parameters for a data miner. An extensive empirical case study for hyperparameter tuning in defect prediction to questions the versatility of tuning’s usefulness while proposing future research and expanding the definition of tuning.
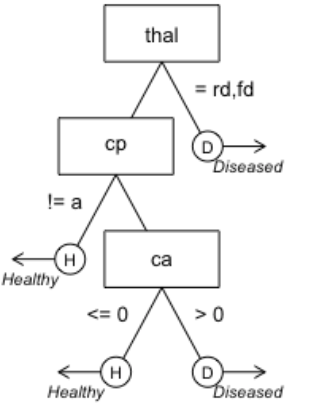
Huy Tu, Amritanshu Agrawal
Automated Software Engineering (ASE), 2018 [Revising]
Novel combination method of LDA topic modeling and Fast Frugal Tree (depth of 4) to predict the severeness of software bug reports. Offers comparable performance but simpler (25%-250% smallerin scale) and faster (50 times faster) than the state-of-the-art text mining models (TFIDF+SVM and LDADE+SVM).
What I know













